
简介
在查询优化的过程中,你应该听从 Markus Winand 的意见。在阅读 这篇关于嵌套循环的文章 时,我遇到了以下评论
查询有预期的左连接,但也包含一个不必要的 DISTINCT 关键字。不幸的是,JPA 不提供单独的 API 调用来过滤重复的父项条目,同时不去去重子记录。SQL 查询中的 DISTINCT 关键字令人担忧,因为大多数数据库实际上会过滤重复的记录。只有少数数据库认识到在这种情况下,主键仍然保证了唯一性。
嵌套循环
领域模型
为了测试,让我们假设我们想要开发一个书店应用程序。在我们系统中最重要的两个实体是 Book 和编写这本书的 Person。
为了简化我们的设计,我们假设每本 Book 都由一个作者编写,尽管在现实中这并不总是如此。因此,领域模型看起来是这样的
@Entity(name = "Person") @Table( name = "person")
public class Person {
@Id @GeneratedValue
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@OneToMany(mappedBy = "author", cascade = CascadeType.ALL)
private List<Book> books = new ArrayList<>( );
public Person() {}
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void addBook(Book book) {
books.add( book );
book.setAuthor( this );
}
//Getters and setters omitted for brevity
}
@Entity(name = "Book") @Table( name = "book")
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
@ManyToOne
private Person author;
public Book() {}
public Book(String title) {
this.title = title;
}
//Getters and setters omitted for brevity
}每本 Book 都有一个 author 属性,表示编写这本书的 Person。
使用 DISTINCT
假设我们需要选择特定的作者,我们可能想要提供一个姓氏列表,以便用户可以缩小作者列表。这可以通过以下查询轻松完成:
List<String> lastNames = entityManager.createQuery(
"select distinct p.lastName " +
"from Person p", String.class)
.getResultList();
assertTrue(
lastNames.size() == 2 &&
lastNames.contains( "King" ) &&
lastNames.contains( "Mihalcea" )
);正如预期的那样,Hibernate生成了以下SQL查询:
SELECT DISTINCT
p.last_name as col_0_0_
FROM person p在这种情况下,使用DISTINCT是可理解的,因为我们希望删除重复项。
到目前为止,一切顺利。但是,现在假设我们想要获取所有Person实体及其Book(s)。
List<Person> authors = entityManager.createQuery(
"select p " +
"from Person p " +
"left join fetch p.books", Person.class)
.getResultList();
authors.forEach( author -> {
log.infof( "Author %s wrote %d books",
author.getFirstName() + " " + author.getLastName(),
author.getBooks().size()
);
} );在执行上述查询时,Hibernate生成了以下输出:
SELECT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 books如我们所见,我们有一个关于Gavin King的重复条目。这是因为我们在我们的ResultSet中有4条记录,数量由与当前选定的作者关联的书籍数量给出。
为了删除重复条目,JPA提供了DISTINCT关键字。
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.getResultList();
authors.forEach( author -> {
log.infof( "Author %s wrote %d books",
author.getFirstName() + " " + author.getLastName(),
author.getBooks().size()
);
} );这一次,Hibernate生成了以下输出:
SELECT DISTINCT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 books不再有重复项。Hibernate在从JDBC获取ResultSet之后构建实体图时删除重复项。
发现问题
然而,你是否注意到了SQL查询中的DISTINCT关键字?在这种情况下,DISTINCT没有任何价值,因为我们没有在JDBC ResultSet中找到重复项。这不仅是不必要的,而且DISTINCT可能会导致性能问题,因为结果集必须由查询执行程序排序。
例如,在PostgreSQL上运行前面的查询会产生以下执行计划:
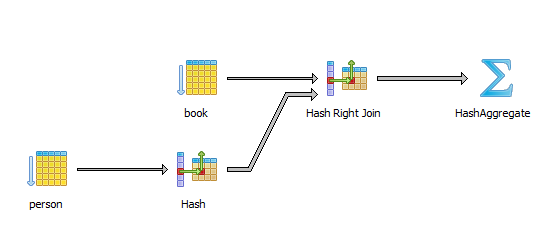
与排序结果集和确保没有重复条目相关的HashAggregate阶段。在depesz.com上有一篇关于HashAggregate内部工作的非常棒的解释[链接](https://www.depesz.com/2013/05/19/explaining-the-unexplainable-part-4/)。基本上,结果集被排序,以便重复的行一个接一个地出现,因此如果某一行与上一行相同,则会被丢弃。
当在MySQL上对使用DISTINCT的相同查询运行EXPLAIN FORMAT=JSON时,我们得到以下执行计划:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "5.02"
},
"duplicates_removal": {
"using_temporary_table": true,
"using_filesort": false,
"nested_loop": [
{
"table": {
"table_name": "p",
"access_type": "ALL",
"rows_examined_per_scan": 3,
"rows_produced_per_join": 3,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.60",
"prefix_cost": "1.60",
"data_read_per_join": "4K"
},
"used_columns": [
"id",
"first_name",
"last_name"
]
}
},
{
"table": {
"table_name": "b",
"access_type": "ALL",
"possible_keys": [
"FKi7lkcmacourlqkkn4uo1s4svl"
],
"rows_examined_per_scan": 4,
"rows_produced_per_join": 12,
"filtered": "100.00",
"using_join_buffer": "Block Nested Loop",
"cost_info": {
"read_cost": "1.02",
"eval_cost": "2.40",
"prefix_cost": "5.02",
"data_read_per_join": "9K"
},
"used_columns": [
"id",
"title",
"author_id"
],
}
}
]
}
}
}|
从MySQL 5.6.5或更高版本开始,您可以选择使用JSON EXPLAIN格式,与传统的EXPLAIN输出相比,它提供了大量信息。 |
您很容易发现与由DISTINCT关键字引起的排序阶段相关的duplicates_removal和using_temporary_table属性。MySQL创建一个临时表来存储中间结果集,并应用排序算法以发现重复项。MySQL提供了一个[DISTINCT/GROUP BY优化技术](https://dev.mysqlserver.cn/doc/refman/5.7/en/group-by-optimization.html)来避免创建临时表,但这需要具有与SELECT查询中相同列和相同顺序的索引。在我们的情况下,这并不可行。
|
|
解决问题
这正是最近解决的HHH-10965问题的主要原因,该问题添加了以下JPA级查询提示:
List<Person> authors = entityManager.createQuery(
"select distinct p " +
"from Person p " +
"left join fetch p.books", Person.class)
.setHint( QueryHints.HINT_PASS_DISTINCT_THROUGH, false )
.getResultList();hibernate.query.passDistinctThrough提示告诉Hibernate不要将DISTINCT关键字传递给实际的SQL查询。因此,我们得到以下输出:
SELECT
p.id as id1_1_0_,
b.id as id1_0_1_,
p.first_name as first_na2_1_0_,
p.last_name as last_nam3_1_0_,
b.author_id as author_i3_0_1_,
b.title as title2_0_1_,
b.author_id as author_i3_0_0__,
b.id as id1_0_0__
FROM person p
LEFT OUTER JOIN book b ON p.id=b.author_id
-- Author Gavin King wrote 2 books
-- Author Stephen King wrote 1 books
-- Author Vlad Mihalcea wrote 1 books这样,Hibernate就消除了Person的重复项,而SQL查询中不再包含无用的DISTINCT关键字。
现在,PostgreSQL的查询计划如下:
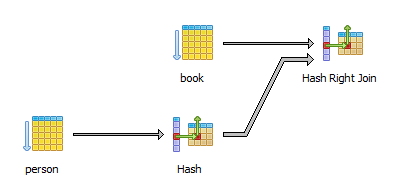
不再有HashAggregate阶段,这意味着数据库没有进行任何多余的结果集排序。
MySQL的查询计划如下:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "5.02"
},
"nested_loop": [
{
"table": {
"table_name": "p",
"access_type": "ALL",
"rows_examined_per_scan": 3,
"rows_produced_per_join": 3,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.60",
"prefix_cost": "1.60",
"data_read_per_join": "4K"
},
"used_columns": [
"id",
"first_name",
"last_name"
]
}
},
{
"table": {
"table_name": "b",
"access_type": "ALL",
"possible_keys": [
"FKi7lkcmacourlqkkn4uo1s4svl"
],
"rows_examined_per_scan": 4,
"rows_produced_per_join": 12,
"filtered": "100.00",
"using_join_buffer": "Block Nested Loop",
"cost_info": {
"read_cost": "1.02",
"eval_cost": "2.40",
"prefix_cost": "5.02",
"data_read_per_join": "9K"
},
"used_columns": [
"id",
"title",
"author_id"
],
"attached_condition": "<if>(is_not_null_compl(b), (`hibernate_orm_test`.`b`.`author_id` = `hibernate_orm_test`.`p`.`id`), true)"
}
}
]
}
}这个修复将包含在Hibernate 5.2.2中,所以升级又多了一个理由!
如果您喜欢这篇文章,您可能还对我的书[链接](https://leanpub.com/high-performance-java-persistence)感兴趣。
