
概述
我相信这可能是大家最期待的文章之一。它将深入探讨RichFaces迭代组件,涵盖我们底层使用的先进模型。实际上,真正的企业应用使用大量数据集,应用分页和延迟数据加载,使用排序、过滤、选择等特性,使应用程序真正丰富和交互。因此,在大多数情况下,您不能仅依赖于简单的列表或使用默认模型包装的数据。为了获得最佳RichFaces表格体验,并具有良好的性能和可扩展性,您需要了解我们模型的基本原理。
模型示例
首先,我想介绍一个在实时演示中可用的新示例 - 可排列模型示例。它使用Hibernate实体管理器,所有分页/排序/过滤操作实际上都在数据库级别执行,而不是在包装的模型中执行。
在这篇文章中,我将指导您了解该示例中的基本点,以便您能够获取主要思想并能够处理自己的模型。
为什么我们需要模型
让我们从一个好问题开始 - 为什么RichFaces引入了具有JSF javax.faces.model.DataModel 合约的定制模型。原因很简单。与仅提供基本功能的JSF 2实现不同,RichFaces引入了新的丰富组件,并在它们之上添加了新功能。以下是一个概述
- 树组件家族。支持基于Swing的数据模型和RichFaces定制数据模型。具有附加提供程序,允许从任何自定义非层次模型声明性创建数据模型。具有选择功能,并可通过不同的模式(Ajax、客户端、服务器)使用。
- 表格组件家族。RichFaces统一了两个富表格之间的排序/过滤/分页功能。它在rich:dataTable中添加了创建主从布局的能力,并内置了折叠/展开子表格的细节。它还通过rich:extendedDataTable添加了垂直滚动和选择数据的Ajax懒加载。等等。
当然,所有这些都需要良好的模型基础。为了标准化不同组件之间的API,并为RichFaces开发者提供一个统一的合约,我们设计了我们的模型。
扩展数据模型概述
从开始,让我介绍一下我们的模型原则,然后我们将在展示演示中看到它们的实现。
扩展数据模型是一个基础模型抽象类,为所有其他模型的特定实现提供合约。让我们更详细地看看这个类
public abstract class ExtendedDataModel<E> extends DataModel<E> {
public abstract void setRowKey(Object key);
public abstract Object getRowKey();
public abstract void walk(FacesContext context, DataVisitor visitor, Range range, Object argument);
}
好吧,我们看到那里引入了一个新的实体。它是rowKey。让我们看看这个实体的目的。在处理复杂的数据结构(如树)和使用高级UI组件功能(如表格中的过滤/排序/分页/选择)时,我们需要有一种简单的方法来识别模型中的对象。仅使用rowIndex并不能很好地解决问题,因为它需要额外的复杂查找机制(根据索引识别包装模型中的数据库对象)来完成这个任务。而使用rowKey,你可以简单地使用在数据库层面使用的相同ID。
此外,你还看到那里引入了walk()方法。RichFaces迭代组件在处理模型时使用访问者模式。因此,该方法应执行模型迭代,并调用作为参数传递的访问者以处理模型中的每个对象。
扩展数据模型的实现
- SequenceDataModel – 表格的ExtendedDataModel的默认实现。当组件不使用过滤和排序时使用。
- ArrangeableModel – 实现ExtendedDataModel的模型,它还实现了Arrangeable接口,用于添加排序和过滤支持。
- TreeSequenceKeyModel 抽象模型以及所有扩展它的模型都用于树组件家族。该模型超出了本文的范围。
示例代码
首先,我想说的是,我不会描述示例中使用的所有代码。你可以很容易地在展示的实时示例中检查它,或者从SVN仓库中获取,并在你喜欢的IDE中探索。除了这将很无聊并且会使文章变得非常大之外,我还想说的是,这篇写作的目的是在审查RichFaces数据模型使用原则时引导你走向正确的方向。
该示例功能概述
- 根据给定的过滤和排序规则从数据库中获取Person对象列表
- 使用rich:dataTable显示对象
- 添加控制排序和过滤的控件
- 添加rich:dataScroller,允许将数据从数据库分页加载。
示例代码 – 基础人员实体
我相信这将是显而易见的。我们只是使用简单且常用的类来定义人员对象。
@Entity
public class Person {
private String name;
private String surname;
private String email;
@Id
@GeneratedValue
private Long id;
//getters and setters
}
示例代码 – 通用模型
现在让我们更详细地看看模型代码。
JPADataModel– 是一个通用模型,旨在为所有实现者提供统一的数据工作方法。它由应定义为在实现它的模型中工作特定实体类的类参数化。此外,它还传递了EntityManager,以便实现者类负责特定EntityManager的查找。
此外,你应该从一开始就注意抽象的getId(T t)方法,该方法也应由实现该抽象模型的模型实现。它应返回特定实体的ID,该ID将用作该模型中的rowKey。
现在让我们回顾两个最重要的方法。让我们从arrange()方法开始。它可能太简单了,所以没有列出,但无论如何
public void arrange(FacesContext context, ArrangeableState state) {
arrangeableState = state;
}
我只是想简单解释一下为什么我们不进行任何进一步处理,只将传递的状态简单存储在模型的属性中。如果您查看或已经查看过RichFaces源代码,您会看到默认的ArrangeableModel实现的该方法执行实际的排序和过滤。但这是因为在我们的默认模型中,我们使用包装模型(例如,作为rich:dataTable值传递的简单列表或映射)。但在我们的情况下,我们将根据当前数据表页面从数据库加载数据,并使用数据库查询进行排序和过滤。所以,我们只需要将组件传递的所有信息存储在ArrangeableState对象中,以供未来在walk()中使用。
现在让我们看看walk()方法
@Override
public void walk(FacesContext context, DataVisitor visitor, Range range, Object argument) {
CriteriaQuery<T> criteriaQuery = createSelectCriteriaQuery();
TypedQuery<T> query = entityManager.createQuery(criteriaQuery);
SequenceRange sequenceRange = (SequenceRange) range;
if (sequenceRange.getFirstRow() >= 0 && sequenceRange.getRows() > 0)
{
query.setFirstResult(sequenceRange.getFirstRow());
query.setMaxResults(sequenceRange.getRows());
}
List<T> data = query.getResultList();
for (T t : data) {
visitor.process(context, getId(t), argument);
}
}
组件在生命周期中调用该方法几次,并期望它遍历模型,调用DataVisitor,该访问者将处理每个对象(例如,在渲染阶段对对象的行进行编码)。
除了访问者之外,表格组件还传递了包含有关从哪一行开始获取数据(使用第一个属性定义或由rich:dataScroller在切换页面时设置)以及要获取的行数的Range对象。所以我们在这里所做的一切——只是创建具有给定排序、过滤和范围参数的查询,将数据从数据库加载到实体列表,并最终遍历该列表,将每个对象传递给DataVisitor进行处理。您可能对createSelectCriteriaQuery()方法很感兴趣,因为它执行实际的排序和过滤参数应用。但实际上,我只想把它留给你,因为JPA查询创建问题超出了这篇文章的范围,并且已经在更具体的资源中得到了很好的解释。
除了您可能对getRowCount()方法感兴趣之外
@Override
public int getRowCount() {
CriteriaQuery<Long> criteriaQuery = createCountCriteriaQuery();
return entityManager.createQuery(
criteriaQuery).getSingleResult().intValue();
}
因此,在那里我们应用排序和过滤,创建标准以返回当前组件状态的rowCount。
示例代码——特定模型类
我们的通用模型实现放在PersonBean中,并使用以下代码定义
@ManagedBean
@SessionScoped
public class PersonBean implements Serializable {
//...
private static final class PersonDataModel extends JPADataModel<Person> {
private PersonDataModel(EntityManager entityManager) {
super(entityManager, Person.class);
}
@Override
protected Object getId(Person t) {
return t.getId();
}
}
//...
private EntityManager lookupEntityManager() {
FacesContext facesContext = FacesContext.getCurrentInstance();
PersistenceService persistenceService =
facesContext.getApplication().
evaluateExpressionGet(facesContext, "#{persistenceService}",
PersistenceService.class);
return persistenceService.getEntityManager();
}
public Object getDataModel() {
return new PersonDataModel(lookupEntityManager());
}
//...
}
实际上,我们在那里所做的一切——执行实体管理器的查找,并使用实体类Person和该实体管理器启动特定的模型实现。
示例代码——页面代码
我们在那里使用了两个页面。首先是arrangeableModel-sample.xhtml
<h:form id="form">
<rich:dataTable keepSaved="true" id="richTable" var="record"
value="#{personBean.dataModel}" rows="20">
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="name" />
</ui:include>
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="surname" />
</ui:include>
<ui:include src="jpaColumn.xhtml">
<ui:param name="bean" value="#{personBean}" />
<ui:param name="property" value="email" />
</ui:include>
<f:facet name="footer">
<rich:dataScroller id="scroller" />
</f:facet>
</rich:dataTable>
</h:form>
那里没有什么有趣的地方。我们只是定义了一个指向我们的模型的表格,并包含列,将人员属性和bean的属性传递给它。
第二个是jpaColumn.xhtml
<ui:composition>
<rich:column sortBy="#{property}"
sortOrder="#{bean.sortOrders[property]}" filterValue="#{bean.filterValues[property]}"
filterExpression="#{property}">
<f:facet name="header">
<h:commandLink action="#{bean.toggleSort}">
#{bean.sortOrders[property]}
<a4j:ajax render="richTable" />
<f:setPropertyActionListener target="#{bean.sortProperty}"
value="#{property}" />
</h:commandLink>
<br />
<h:inputText value="#{bean.filterValues[property]}">
<a4j:ajax render="richTable@body scroller" event="keyup" />
</h:inputText>
</f:facet>
<h:outputText value="#{record[property]}" />
</rich:column>
</ui:composition>
这对我们来说更有趣。您应该注意的最重要的事情是我们将Person属性名称作为sortBy和filterExpression值传递。通常,您会使用EL绑定来迭代对象属性和布尔表达式,如果您使用我们默认的模型。但对我们来说不是这样。因为我们实现了我们的模型,其中包含数据库排序和过滤——我们只需要知道属性名称,我们将在查询中应用规则,就像您在模型中看到的那样。
练习
当然,这个样本仍然不是理想的。最重要的是,你可以轻易地看出绝对没有缓存。每次调用 walk() 或 getRowCount() 时,都会查询数据库以请求数据。你应该自己添加,因为实际上没有适用于所有情况的统一方案。有人可能只需要在过滤、排序或页面更改时从数据库中读取一次数据,并确保它不会在请求之间改变。在某些情况下,你应该考虑数据可能由不同用户同时插入/删除/编辑,因此 walk() 方法获得的列表可能在不同的 walk 调用之间改变,等等。因此,这取决于你定义规则。同样的,也适用于 rowCount。非常重要的是也要尽可能缓存它,因为它在请求期间(由表格和数据滚动器)也会多次调用。
此外,你可能还想添加 Weld/Seam,以便能够以更优雅的方式绑定豆、实体和服务。
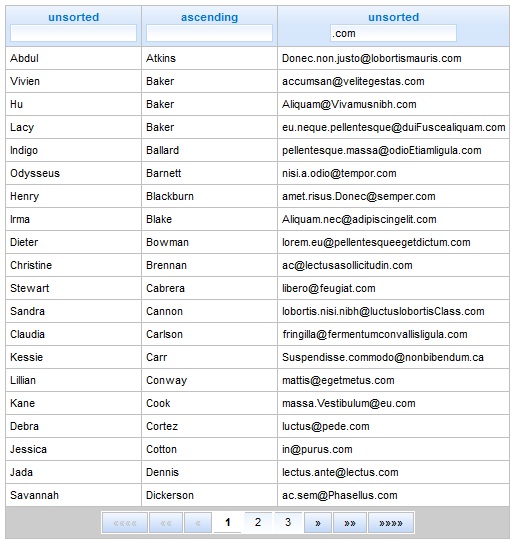
结果
即使考虑到所有这些,如果你没有至少一张结果的截图,这篇文章的演示就会显得很无聊。所以,这里是我们在执行了 按姓氏排序 和通过电子邮件进行筛选(仅获取 .com
域的电子邮件)后得到的表格。
更多信息
如往常一样,请参阅 RichFaces 文档 以获取更多信息和 JavaDoc 的引用。
